Authing 后端除了 OAuth、OIDC、SAML 等协议接口外,全量使用了 GraphQL,总计达 500 余个,在此过程中积累了大量的实践经验和最佳实践,在此分享给大家。
在此系列文章中,我们将会分享以下主题:
- 为什么使用 GraphQL?
- 什么是 N+1 问题以及如何解决?
- 如何设计 GraphQL Schema?
- 如何做 API 版本管理以及维护 backward compatible?
- 如何在 GraphQL 中进行认证和授权?
- 如何测试 GraphQL 接口?
- 如何统一处理接口错误?
- ...
同时,在 9 月份 Authing开源了一款 GraphQL 调试器,上面有我们暴露给开发者的接口。GitHub 地址:https://github.com/Authing/super-graphiql,可以前往https://authing.cn/graphiql/在线体验。
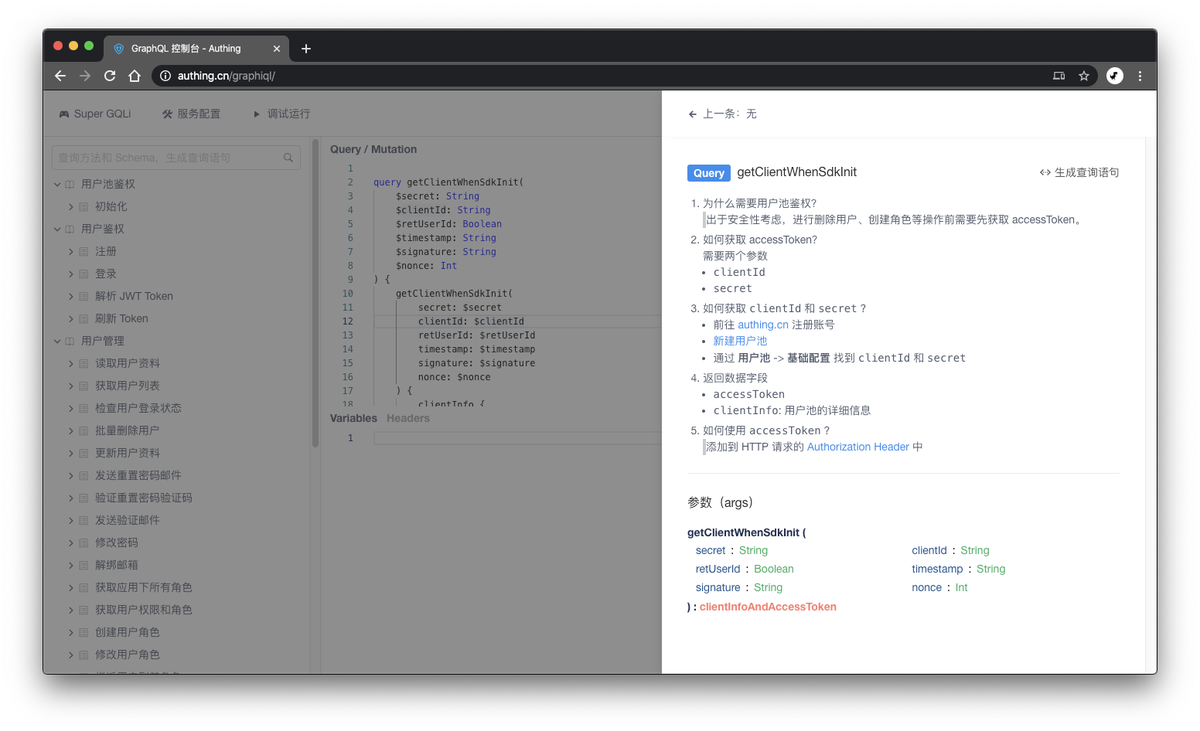
为什么使用 GraphQL ?
显示声明
在https://graphql.org/,官方是这样介绍 GraphQL 的:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
其中重要的关键词:complete and understandable description of the data in your API、gives clients the power to ask for exactly what they need and nothing more,也即天然地 API 自文档化、客户端需要什么就显式地声明什么。
通过这张图能很好得说明这一点:
- 描述数据
- 显式声明需要哪些数据
- 得到符合预期的结果

这也是我最喜欢的一点:没有 select *,调用者需要什么,就显式地声明相关字段。
这样有几个好处:
- 得到的结果可以肯定是符合预期的(接口语法层面的 break change 会在 GraphQL 过滤层就会被拦截掉),不需要担心后端接口改动 break 掉已有的项目。
- Client 不会过度获取数据。REST 接口经常遇到多处使用同一个接口时,往往会出现拉取了过多数据的问题,造成带宽和计算资源的浪费。
- 前端所需数据的变化不一定需要变动接口。
拿 Authing 的接口举个例子:这是 user 接口(查询用户详情)返回数据的定义,里面有几十个字段:
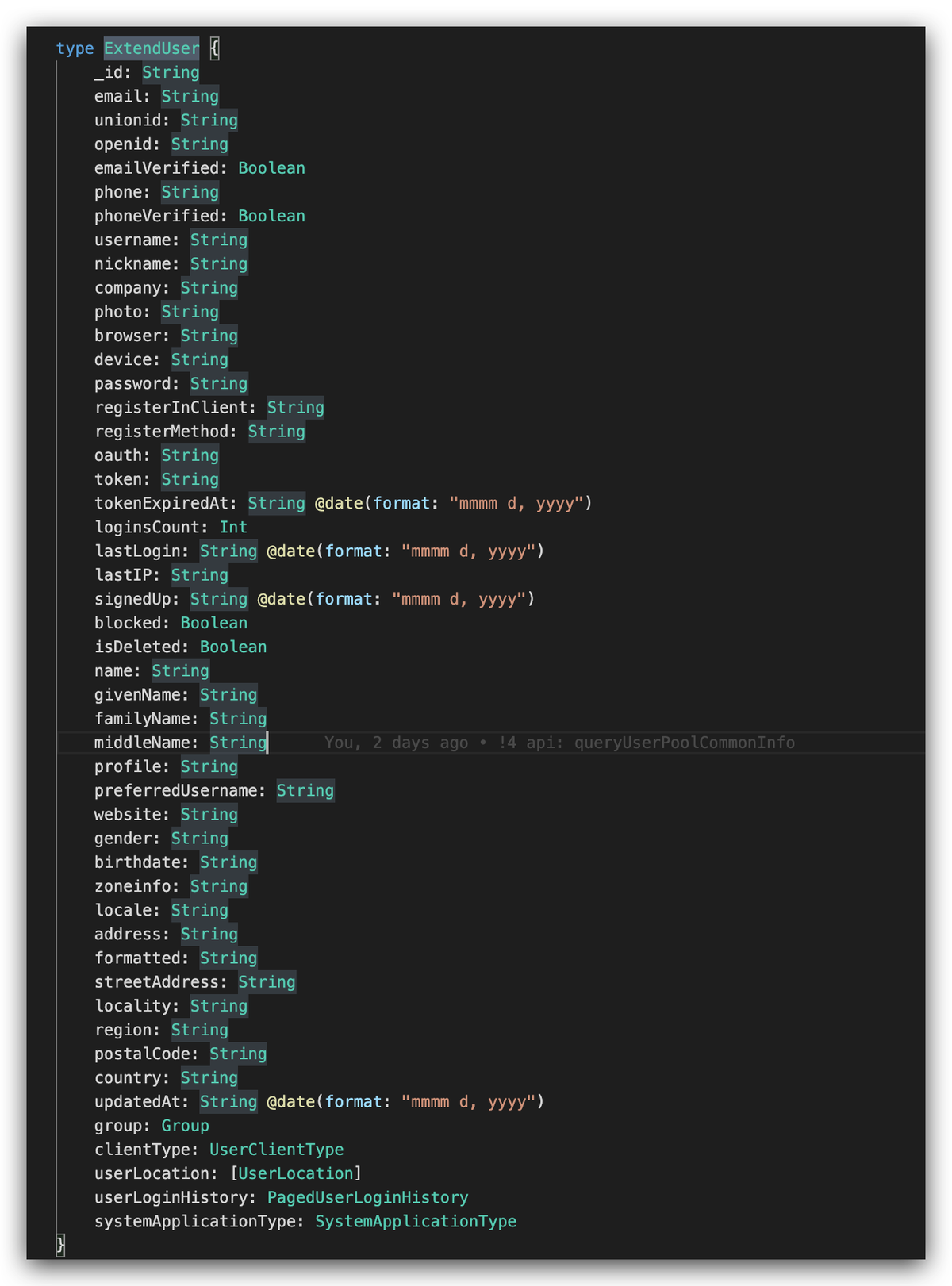
但是不是所有场景都需要这么多数据,比如 Authing 后端有一个根据用户 ID 查询用户基础信息的接口,只需要用到用户名、头像、邮箱,这时候就只需要显示声明使用 _id photo username email这几个字段就行了。如果用的是是 REST API,很可能需要额外使用不同的接口,或者将所有数据一股脑返回。
强类型
对大多数API而言,最大的问题在于缺少强类型约束。常见场景为,后端API更新了,但文档没跟上,你没法知道新的API是干什么的、怎么用。
GraphQL 强类型有以下好处:
- 使得一些语法层面上的错误在编译阶段就显示出来。
- 客户端调用接口时如果填错了字段名,会显式报错,这对于调试来说是很有用的。
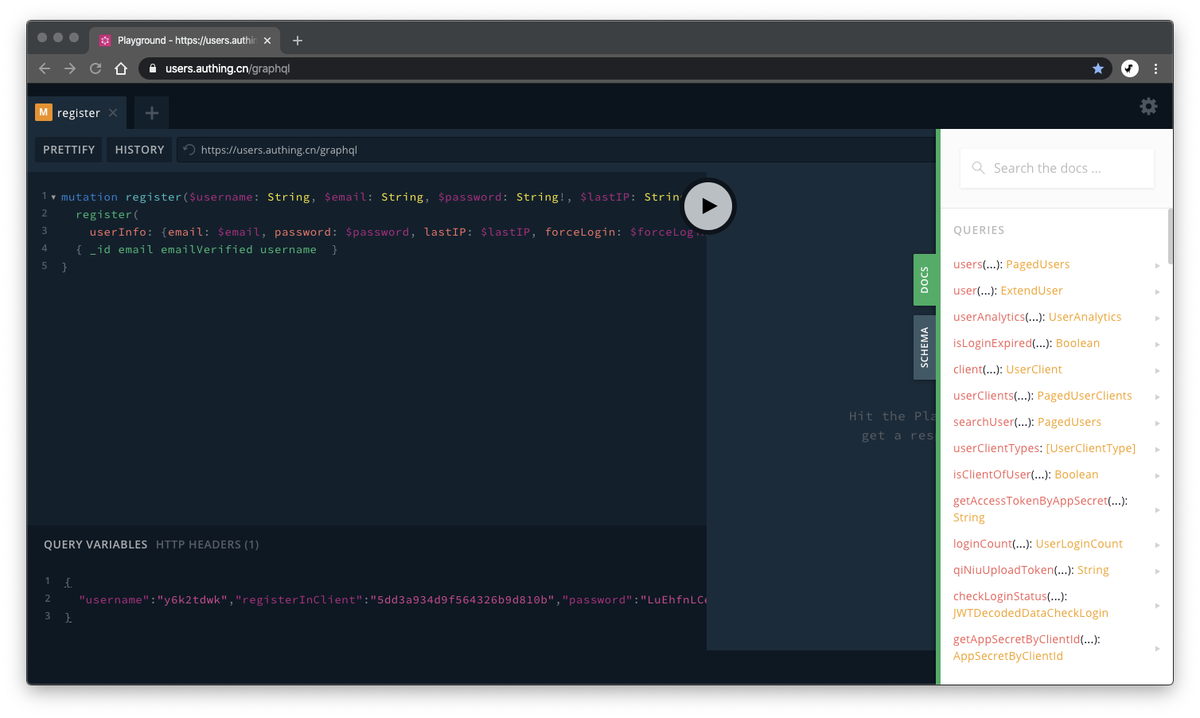
- 自文档化:相关工具(如 apollo-graphql )可以根据 GraphQL schema 自动生成一个在线的调试器:
 优秀的社区支持
优秀的社区支持
Authing 做技术选型,很看重整个开发者社区的活跃程度,因为这意味着代码的质量保证以及发现问题修复的速度。GraphQL 由 Facebook 发布,GitHub API V4 也开始使用 GraphQL 取代 REST,同时有越来越多的开发者和公司选用了 GraphQL 作为 API 首选,在可以预见的未来,GraphQL一定会成为趋势。

什么是 N+1 问题以及如何解决?
我们都知道软件行业没有银弹,总是需要在某些方面之间进行取舍。GraphQL 也不例外,存在着某些问题,但是既然我们已经决定了要使用 GraphQL,那么就得想办法尽可能解决这些问题。
GraphQL 最受人诟病的一个问题是 N+1 问题,如果你对此不是很熟悉,我们先简要介绍以下:还是以 Authing 的实际场景举例子:Authing 有一个查询用户池中用户最近登录情况的的接口,为了可读性,我把代码转成了 Python 形式:其中 loginHistory 是单独存表的。
def get_user_login_history_of_userpool(userPoolId):
users = Users.objects.filter(userPoolId = userPoolId)
for user in users:
print(user.loginHistory)相信聪明的你应该发现问题所在了:这里进行了 N + 1 次查询!首选通过一次查询获取用户池所有用户ID,然后遍历用户 ID 列表,获取该用户对应的登录记录。转成 sql 语句是这样的:
SELECT user_id
FROM users WHERE userPoolId = 'xxxxxxxxxxxxx';
// 假装有三个用户
SELECT *
FROM user_login_history
WHERE user_id in (1);
SELECT *
FROM user_login_history
WHERE user_id in (2);
SELECT *
FROM user_login_history
WHERE user_id in (3); 这样效率肯定是很低的,要是能够将 sql 转换成下面这种就好了:
SELECT user_id
FROM users WHERE userPoolId = 'xxxxxxxxxxxxx';
SELECT *
FROM user_login_history
WHERE user_id in (1, 2, 3);从这里我们可以得出一点结论:N + 1 问题更多的是一种代码设计缺陷且肯定是有解的,这在 REST 接口中更容易解决,可惜的是,在 GraphQL 中,我们并不能很容易得做到这一点,下面解释以下为什么。
这要了解一点 GraphQL 的运行方式。GraphQL 官方文档是这么说的:
You can think of each field in a GraphQL query as a function or method of the previous type which returns the next type. In fact, this is exactly how GraphQL works. Each field on each type is backed by a function called theresolverwhich is provided by the GraphQL server developer. When a field is executed, the correspondingresolveris called to produce the next value.
简要解释一下:一个 GraphQL 查询语句中的字段,可以看作它的父类型的一个方法。每个字段都对应了一个 resolver 函数,当获取该字段的值时,它所对应的 resolver 函数就会被执行。
以 Authing 查询用户池用户最近登录情况接口为例:
query GetUserLoginHistoryOfUserPool($userPoolId: String!){
userLoginHistoryOfUserPool(userPoolId: $userPoolId){
user{
_id
name
avatar
loginHistory {
_id
when
ip
success
browser
device
}
}
}
}user 类型中的 loginHistory 字段,实际上对应的是一个 resolver 函数, GraphQL 执行的时候,会把当前 user 对象传给 loginHistory 的 resolver 函数,此 resolver 函数会从 user 对象中取出 userId,然后去数据库查询历史登录数据。这就是 N + 1 问题来源的本质:GraphQL 执行时在 user 这一层,会获取 user 列表,然后对每一个 user 对象,单独执行一次 loginHistory resolver 方法,这样当然也就不可避免地造成了这样的查询语句:
SELECT user_id
FROM users WHERE userPoolId = 'xxxxxxxxxxxxx';
// 假装有三个用户
SELECT *
FROM user_login_history
WHERE user_id in (1);
SELECT *
FROM user_login_history
WHERE user_id in (2);
SELECT *
FROM user_login_history
WHERE user_id in (3); 更多有关 How GraphQL execution Works 的内容可以看GraphQL Execution 部分的官方文档。
当然这个问题是有解的,这个解就是dataloader!
相信通过一个具体的例子你能很快理解:首选我们定义一个 batch load 函数,接收用户 ID 列表,返回一个包含所有用户历史登录的 Promise。
async function batchUserLoginHistory(userIds) {
const results = await db.fetchAllLoginHistory(userIds)
return userIds.map(userId => results[userId] || new Error(`No result for ${userId}`))
}
const loader = new DataLoader(batchUserLoginHistory)这里的 fetchAllLoginHistory 会接收用户 ID 列表,返回所有用户历史登录数据,返回值格式如下:
{
1: [
{
when: "xxx",
success: true,
browser: "xxx"
}
],
2: [],
// ...
}其中 key 作为用户 ID,value 为对应的登录历史记录。
然后在 loginHistory 的 resolver 函数,当我们需要查询数据库的时候,调用上面定义的 loader 对象的 load 方法:
const loginHistory = await loader.load(1)如果在其他地方也需要一样的查询,也可以这样调用:
const loginHistory = await loader.load(2)DataLoader will coalesce all individual loads which occur within a single frame of execution (a single tick of the event loop) and then call your batch function with all requested keys.
dataloader 会将 Node.js 事件循环一个 tick 内所有的 load 调用合并到一次查询!
除了 batching 功能,dataloader 还支持 per-request cache。在同一个 request 中,dataloader 会缓存 特定 key 调用 load 函数的结果。
DataLoader is first and foremost a data loading mechanism, and its cache only serves the purpose of not repeatedly loading the same data in the context of a single request to your Application. To do this, it maintains a simple in-memory memoization cache (more accurately:.load()is a memoized function).
这样,我们就既保持了代码的美感,又没有牺牲系统的性能。
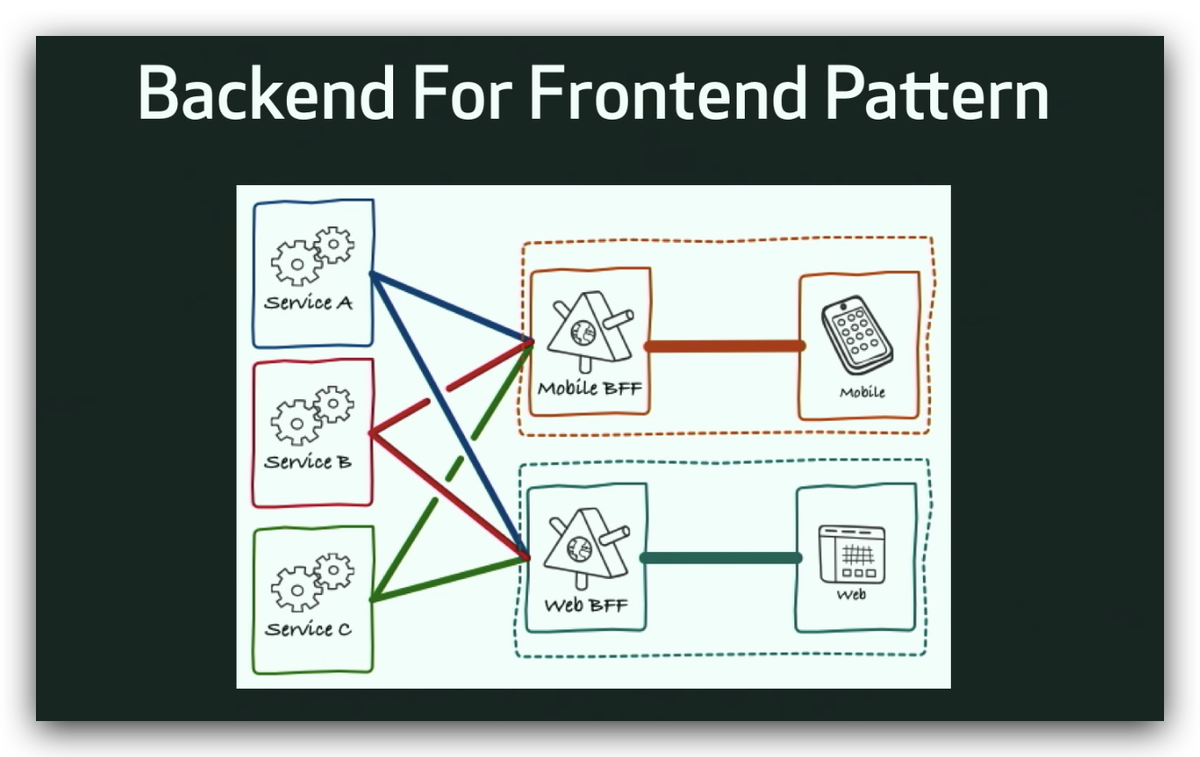
如何设计 GraphQL Schema 和 API?
problem:multi client with different needs
pattern:backend for frontend,bff


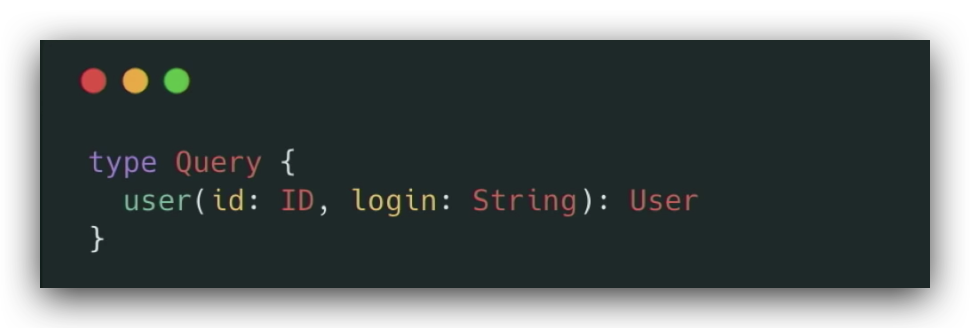
- Id 和 login 都是 nullable
- 如果同时传了 id 和 login 怎么办?
- 如果都没传怎么办?
几个设计原则:
- Focus on use case/ behavior over data
- Minimize client change - helper field
- Both Atomicity vs granularity
- 将检验参数是否合法的工作交给 graphql 的语法层。
- Build granularity api interface
- Stay away from build a "one size fit all " api



